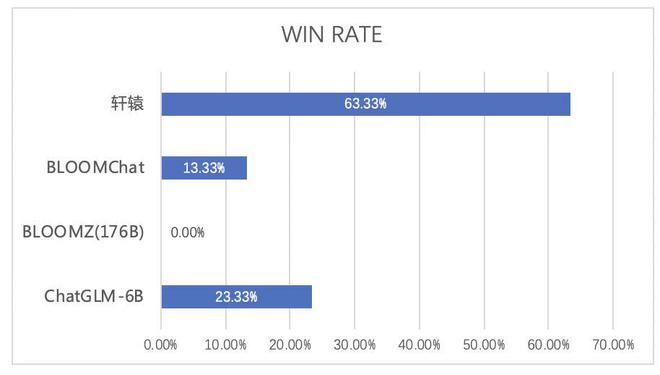
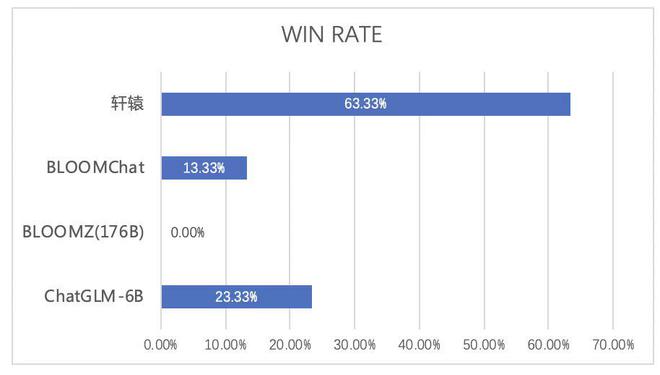
5月26日消息,近日,度小满正式开源千亿级中文金融大模型——“轩辕”。轩辕大模型是在1760亿参数的Bloom大模型基础上训练而来,在金融名词理解、金融市场评论、金融数据分析和金融新闻理解等任务上,效果相较于通用大模型大幅提升。
据度小满方面介绍,在金融场景中的任务评测中,轩辕全面超越了市场上的主流开源大模型,赢得了150次回答中63.33%的胜率。在通用能力评测中,轩辕有10.2%的任务表现超越ChatGPT 3.5,61.22%的任务表现与之持平,涉及数学计算、场景写作、逻辑推理、文本摘要等13个主要维度。
为了提升轩辕大模型对金融领域问题的理解能力,度小满将自身业务中积累的金融领域的千亿tokens的中文预训练数据集用来训练模型。该数据集涵盖了金融研报、股票、基金、银行、保险等各个方向的专业知识。度小满表示,经过清洗和标注的高质量数据集,不仅在通用性方面与ChatGPT达到持平成为可能,且提升了模型在金融垂直领域的性能。
BLOOM (Big Science Language Open-science Open-access Multilingual)是2021年由1000多名志愿研究人员在一个名为“大科学BigScience”的项目中创建,2022年7月12日正式发布。BLOOM拥有1760亿个参数(决定输入数据如何转换为输出内容的变量),稍多于拥有1750亿个参数的 GPT-3。BLOOM拥有1.61TB文本,包含46种自然语言和13种编程语言。相比Meta发布的130亿参数的LLaMA(Large Language Model Meta AI)模型,Bloom参数量更占优势。
目前,千亿级的轩辕模型已可以在Huggingface中申请下载,面向所有金融机构开放。
度小满CTO许冬亮表示,轩辕大模型是经度小满业务场景中积累的金融数据训练而来的,对金融相关问题的理解比通用大模型更有优势。我们把大模型能力开放给金融机构,有利于推动大模型在金融行业的应用,降低大模型的应用门槛,提升金融行业智能化水平。
许冬亮认为,生成式大模型在内容生成与创作、信息摘要与总结、知识理解与问答、自然交互与对话等方面具备非常出色的能力,在金融场景中会有广泛的应用。在前台,生成式大模型将大幅提升客户经理的专业水平和服务能力,大幅降低客户经理的运营成本,让每个人都拥有24小时在线的专业客户经理成为可能。出色的内容生成能力也将引发营销内容生产能力的大幅提升。在中台,生成式大模型有机会改变企业内知识获取、内容创作、会议与沟通、代码开发与测试的方式,进而大幅提升企业内部办公效率,甚至引发研发测试模式变革,全方位的提升金融企业内部运营效率。在后台,大模型将成为智能科技底座的标配,大幅降低智能技术应用的门槛,只需少量标注数据甚至无需调整就可以让智能技术覆盖广泛的场景。(一橙)





