
人工智能作为当下最热门的话题,我们一边为技术取得的重大进步欢欣鼓舞,一边又为它过于强大的能力感到不安。它不只是计算机学家的课题,而是涉及到科学、政治、社会的方方面面。
北京时间2023年5月24日,美国加州理工学院电气工程与计算机科学Yaser Abu-Mostafa教授带来了该校“沃森讲座”百年纪念日系列的压轴报告“Artificial Intelligence: The Good, The Bad, And The Ugly”。他用通俗易懂的语言解释了人工智能的科学原理,并探讨了其风险和益处。
在“AI会杀死我们所有人”和“AI会解决我们所有问题”的极端观点之间,教授带领我们用科学的观点识别现实和推测,并指导我们在规划、立法和投资中对AI进行决策。
本文对此次讲座进行了整理精简,以飨读者。
揭开人工智能的神秘面纱
如今我们身处在一个人人都在谈论人工智能的时代,但当提起它时,我们有时抱着兴奋与激动,有时却又为它惴惴不安。一方面,人工智能的性能一次又一次的令我们惊艳,另一方面我们并不理解它是如何表现得如此像人类,更不知道它未来会发展到何种程度。为了针对人工智能带来的社会现象制定有意义的政策,我们需要揭开它的神秘面纱,了解其背后的科学原理。
提到人工智能的科学原理,最核心的问题是机器是如何表现智能特征的(symptoms of intelligence)。在神经网络时代到来之前,人工智能领域占主导地位的是依靠暴力算法的专家系统,采用“查找表”的形式,帮助机器迅速的查询到想要的信息。当被问到一个问题时,机器可以迅速的找到答案,表现得十分“聪明”。仅仅依靠暴力算法这样简单的原理,机器便可以轻易在智力竞赛和象棋比赛中击败最强大的人类选手,我们似乎已经取得了智能甚至是超级智能。但这类人工智能需要花费巨大的人力物力来把合适的信息放到合适的位置,只能发挥仅仅一次作用,这显然不是我们所想要的智能的模式。
自1980年以来,人工智能领域发生的最巨大的改变,便是从暴力算法演变成了学习算法。想要理解“学习”和“智能”的关系,我们可以看看自己的大脑,我们拥有一套内置的学习算法:大脑靠神经元传递信息,而在两个神经元之间存在的突触,会依据发生的情况上调或下降连接强度。人类大脑中存在100万亿甚至更多的突触,因此我们的大脑可以存储不胜其数的信息并组织成一种方便回忆和学习的形式。
但我们如何模拟大脑实现学习功能呢?参考我们模仿鸟类制造飞机的发展历程,我们只需要提取出“翅膀”和其背后最核心的特征即可:我们现在的飞机可以完美的实现飞行功能,但并不像真正的鸟类一样扇动翅膀。
因此真正重要的事情是针对不同功能提取出本质核心。那么,从上世纪八十年代发展至今,我们已经提取出了生物神经系统中反映智能的核心了吗?看看人工智能领域的最新进展,我们可以毫不犹豫地回答:是的。

▷图片来源:沃森讲座
在理解了人工智能的智能表征后,我们再来理解人工智能会容易许多。例如在最基本的神经网络结构中,便是多个神经元通过突触相互连接的形式。我们需要注意的正是这些突触——也可以称它们为参数。理解这些参数最好的方式是把它们看作旋扭——我们学习一个函数的过程其实就是通过调节大量的旋钮,尽量让输入的数据在我们构造的神经网络中实现我们期待的功能。这是一个巨大的工作,但好消息是我们拥有学习算法,可以告诉我们在数据输入时如何调节。而一旦调节完成后,旋钮的状态就被固定住了,以完成我们希望网络完成的工作。
除了基本神经网络模型之外,还有许多别的神经网络模型,例如ChatGPT采用的便是“转换器”模型(Transformer),它有着灵活的注意力机制。理解这些不同模型最好的方式是:在我们的大脑中不同脑区的构建单元都是神经元和突触,但它们有不同的结构来实现不同的功能——同样的,当我们想完成不同的任务时,我们应该构建不同的模型。
现在我们可以从信息存储的角度比较一下人工智能的新旧两种形式。以一个具体的例子来说,假设我们现在同时有专家系统和神经网络两个系统来回答同一个问题。
专家系统的工作方式是这样的:它已经提前设定好了并一直保持固定,它所需要做的就是搜寻数据库以便找到正确答案并输出。而对于神经网络来说,问题输入后,它需要多个突触相互交互,经过不断的处理后才能生成最终答案,也就是说,它采取的是一种分布式的编码方式。这样的编码方式使得网络可以柔性地处理每一段信息,让它们相互交互来探索我们从未遇到过的问题。
理解了神经网络的信息存储方式后,我们再来看看人工智能备受争议的一个问题:我们都听说过人工智能是一个黑盒子的说法——我们不能理解它做的事情,我们也就很难相信它。
“可解释性人工智能”的问题其实可以类比人类做决定的过程:你最开始只是有一种直觉,接着你依靠这种直觉做出相应的选择。如果现在请你分析为什么做出了那样的决定,你很可能会解释说有哪些因素影响了你,但如果我缠着你十分精细地阐述你究竟为什么这样做,很可能你也会束手无策。事实上,我们靠直觉做的决策依赖于我们过去人生中不断积累的观察与经验,而这些都是我们无法按照顺序详细记录下来的。这和可解释性人工智能的情形十分相似。当我们想要“理解”人工智能时,你只需要知道它的功能是内嵌在结构中的,而不需纠结于每一个参数的含义。
在讨论人工智能的政策前,我们还需要知道神经网络是如何建成接着发挥功能的。一个网络发挥作用总是要经过构造网络和应用网络两个阶段。构造网络,或者我们常说的训练网络的阶段,正是我们之前所说的调节旋钮的过程,调节旋钮可以使得原本不针对任何任务的网络变成具有一定功能的特定的网络。简单的估算一下,假设我们有一台拥有极大内存的电脑,一个ChatGPT模型需要1.5千亿的参数,想要让一台电脑得到一个ChatGPT模型需要计算200000年。训练网络时网络本身不带有任何“偏见”或目的,它完全由我们设置的训练过程决定。相比训练过程,网络的使用阶段要来得简单得多。一旦训练完成,参数值就已经冻结了,我们只需输入查询语句,模型便会生成答案。
当我们提到管控人工智能时,其实涉及两类管控:第一类是管控人工智能的部署——当一个人训练人工智能时,我们如何确保得到的网络是无害的?如同药监局对上市的药物都要进行核查一样,我们对人工智能也需要设定类似的机构。例如想要检查网络是否带有偏见,我们只需输入一组标准的检测数据,观察输出的结果是否带有偏见,一旦发现不合格的回答,便拒绝推行这类网络。
第二类管控则是管理人工智能的发展,我们常常将人工智能类比为核武器。我们已经有了一套相对成熟的核武器国际管控机制——我们对于核武器的原料“浓缩铀”设定数量上的限制,这样便无法生成安全范围以上的核武器——我们可以对人工智能做类似的事情吗?可惜的是,人工智能所需要的GPU芯片,保守估计已经有一百亿已投入使用。利用计算机领域开源社区的特征,世界上任何一个机构,或者即使最穷的一个国家,也可以制造出他们想要的任何人工智能模型。我们需要看到,在人工智能领域,这里没有“浓缩铀”,人工智能必将实现自己完全的潜力,即使你不做这件事,总有别人来做。
人工智能将去往何处
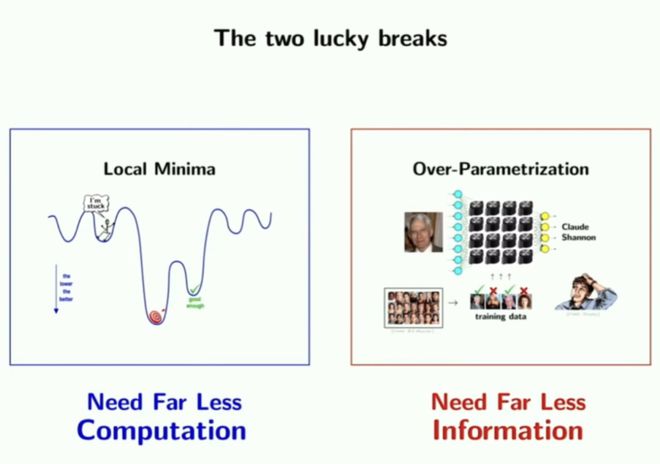
在人工智能领域,最讽刺的事情便是,即使是最智能的网络,也无法预测人工智能的发展将走向何处。我们承诺人工智能能达到什么时,我们不用担心我们虚夸了它的未来,我们担心的是它会远超于我们的预期。为什么会这样呢?因为在我们发展人工智能的过程中,我们十分幸运发展出了“局部最优解”与“过表达”理论,目前有许多相关研究和结论,但是还没有一个概括性的结论。
▷图片来源:沃森讲座
局部最优解的算法使得我们需要耗费相对极少的计算过程,而过表达的训练方式则使我们只需投入远少于参数量的训练数据来得到网络。目前对于各自背后的原理都还没有彻底弄清楚,但这些“运气”使得现在的模型成为可能,这些“运气”还将保证日后的人工智能走得更远更好。
这份运气延续至今的表现具体体现为“涌现”现象:在训练网络过程中,我们不断增加网络中的参数数量,这个过程中网络的性能不是线性增加的。事实上,随着数据量增大,它一开始只是平缓地上升,但到了某一个临界点,网络性能会取得突然的增加。这也正是人工智能不可预测的原因,我们猜测也许在现有基础上继续增加训练数据量,网络将会发生新的涌现,达到现在难以想象的水平,但我们无法预测它将在何时到来,或者也许我们不够幸运,这一天永远不会发生。
人工智能可以“为我们”又可以“对我们”做什么
当我们谈论人工智能带来的好处时,往往会包含两个方面:人类可以做的事情和人类无法做的事情。
医学领域人工智能实现了许多人类无法做的事情,但却没有得到足够的报道,但它们是真正影响我们生命的应用。对于显微镜下的活体切片,想要找出肿瘤是否在该组织中扩散。这个任务对人类来说已经超过了视觉系统检测图像的极限,即使技术最精湛的医生判断时的准确率也不会超过50%。但如果训练一个网络来做这个任务,它的准确率可以达到90%。这是一个很正面的例子,将人工智能应用到医学领域,来拓宽我们的能力,并提高我们的生活质量。
而在我们能做的领域我们也正在被人工智能超越,与工业革命时期比较,当时机器的出现取代了手动生产,解放了人类的体力劳动;而人工智能革命,则是解放了人类的脑力劳动。数字革命与工业革命相比的重要区别在于其发展速度。工业革命花了大约80年的时间,约等于一代人的寿命,因此也提供了下一代人适应的时间。而据预测,人工智能革命产生显著影响只需要短短20年,甚至可能15年(以2012年为起点)。事情发生的如此之快,我们需要做什么呢?我们无法要求所有人停下对人工智能的开发,大范围的失业和混乱是无法避免的:人工智能发展会为我们带来诸多红利,但同样也伴随着生长痛,对当代生活的人来说,他们能感受到的痛苦会大于人工智能带来的便利,我们能做的便是构建合适的安全网,来照顾、重新培训可能面临失业的人。
最后我们讨论一下人工智能的风险,可以分为恶意使用AI、流氓AI系统和社会影响三类。我们都清楚恶意使用人工智能可以实施的犯罪,包括窃取信息、诈骗、非法侵入……立法者和罪犯之间的关系就像猫和老鼠,立法者无法预测有什么样的犯罪行为可能发生,永远只能追在后面跑。因此我建议将“使用AI”作为加重刑罚的因素,而不需要创造新的犯罪条款。我们只需要告诉人们,如果你实施了一项犯罪,并在过程中使用了AI,你的刑罚将变得更严重。这是一个全局的法规,至少可以刹住立马袭来的大范围犯罪的车。
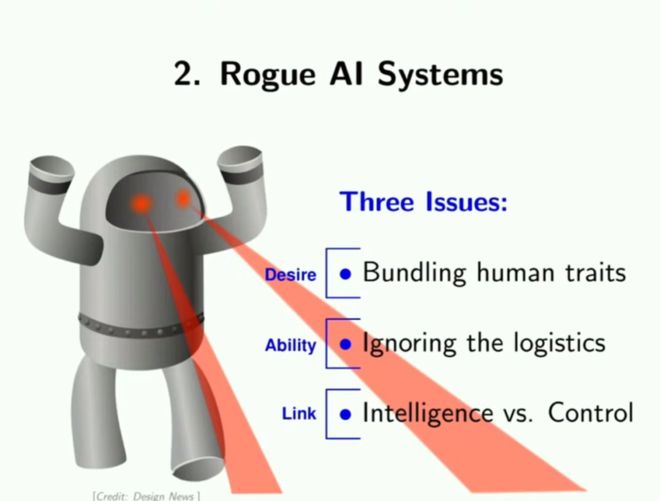
另一个更有意思的话题是流氓AI系统,我们担心人工智能过于聪明,会使我们人类变得低等;甚至有人认为情形将更为复杂:除了我们自己创造的人工智能,AI还会自己来创造更为聪明的AI系统并迅速进化,最终将人类完全边缘化。这显然是一个人类生存上的威胁——如果你相信它的话。但对我来说,我很难赞同这样的观点。我们从来没有和除了人类以外的智能系统打过交道,当我们忽然与ChatGPT交流时,我们往往把其想象为一个人类,一个拥有感受和意识的人类——我们在其身上附加了许多人类的属性,但我们需要看到,智能是一种能力,而支配则是一种欲望,对于纯粹的智能系统来说它们真的有支配的欲望吗?即使真的有,我们也不能忽视AI背后的逻辑——AI训练网络时离不开海量的资源和巨大的能量。我们观察到网络在花费巨大的资源进行自我训练,我们会眼睁睁地看着它在两个月内进行我们没有安排的任务吗?抱歉,我无法相信这样的事情会发生。
▷图片来源:沃森讲座
因此,如果你担心AI可能被人类用于实施犯罪,我完全同意你的观点,但我并不会担心AI自身会变得邪恶。我真正担心的,是AI会造成的社会影响。我们都看到了社交媒体对于青少年的心理健康造成的影响,我们也都体会过新冠时期社交隔离进一步让我们依赖于手机,因此我们可以想象,如果我们的手机变得愈发智能,甚至成为了我们最好的朋友,我们便会变得越来越孤立。但我想强调的是,作为人类,我们有与人接触的本性,即使与刻意设计的人工智能相比,我们身边的人不那么富有同情心、不那么擅长合作、不那么乐于助人。我们需要意识到无论我们的技术发展到何种程度,人工智能只是一个人造的产物,在它的接收端没有任何的人类。
译者按:
人工智能发展如此迅猛,我们没有办法阻止其发展的脚步,但可以选择是否跟上它的浪潮而不被时代淘汰。走出个人的视角,人工智能需要诸多领域的协作来发挥更大的潜能,和实现更稳健而良性的发展。
从人工智能的原理来说,它下一步的发展方向是朝着人脑的数量级前进,因此需要计算机领域和神经科学领域的相互合作与促进。从人工智能的应用角度来看,我们需要制定合理的法律规范其应用,需要合适的社会保障制度来应对它可能带来的冲击……
Abu-Mostafa教授在长达九十分钟的讲座中,向我们介绍了人工智能的前世今生,和即将可能发生的未来,提出了许多恳切并有建设性的建议。他用充满智慧又风趣的讲解带来头脑风暴的同时又引发了每个人对自身领域独特的思考,是一场十分精彩的讲座。





