

通过行业应用先行来带动整体的突破。
文 | 华商韬略 王梦欣
年初以来,OpenAI以ChatGPT在全球掀起AI大模型热潮。但美国的AI大模型,远不止于OpenAI的ChatGPT。
【井喷式发展】
综合各种数据,虽然中国发展势头迅猛,但美国依然是全球发布大模型最多的国家,到2023年5月,其10亿级参数规模以上的基础大模型就已突破100 个。
《经济学人》报道,美国2022年大模型投资总额达474亿美元,是第二名中国(134亿美元)的约3.5倍,且仍保持激增态势。高盛则进一步预测,美国2025年大模型相关投资可达千亿美元,约全球的1/2。
高盛的调查显示,罗素3000指数公司中有16%的公司在2023年的财报会议中提到了大模型,其经济学家估计,大模型将在十年内提高1%的整体劳动生产率,并为标普500指数带来约14%的增长。
除了ChatGPT,美国如今具有代表性的通用大模型公司还包括:Anthropic、Cohere以及Google等。
其中,由OpenAI前高管Dario和Daniela Amodei等人于2021年自立门户创办的Anthropic,目前估值已达300亿美元,是仅次于OpenAI(约860亿美元估值)的通用大模型企业。
Anthropic拥有多位参与过GPT-2与GPT-3研发的前OpenAI核心员工,其大模型产品Claude2也被认为是仅次于ChatGPT-4的经典力作,甚至有分析师认为,Claude2的性能优于ChatGPT-4。
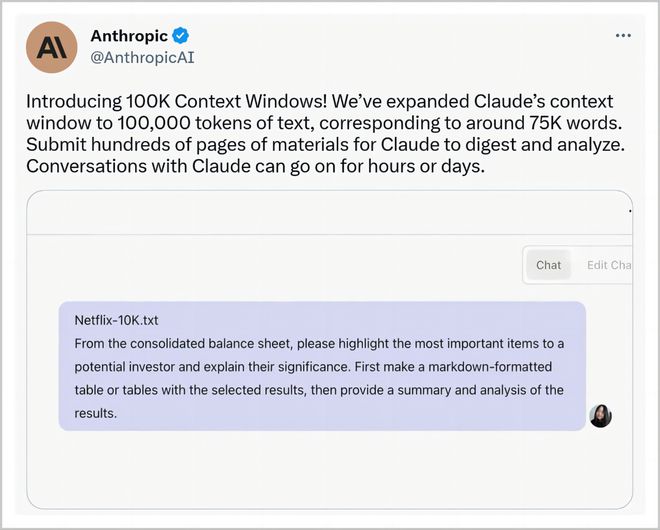
比如,Claude2可以处理多达约75000个单词的数据集,而ChatGPT大约是3000个,这意味着它可以处理和输出更复杂的内容,也被应用到更有挑战性的领域,比如生成数千字的长文内容。
更让Claude2积攒人气的是,它直接免费向公众开放,而不是像GPT-4一样需要付费使用。
优秀的创始团队和强大的产品性能,让Anthropic备受资本追捧,谷歌、韩国最大移动运营商之一SK Telecom(SKT)、亚马逊都已成为其投资者,其中仅亚马逊的投资就高达40亿美元。
在Anthropic之外,还有一家令人称道的公司便是Cohere。
今年6月,2019年创立的Cohere获得NVIDIA、Oracle、Salesforce Ventures等投资的2.7亿美元,成为估值20亿美元的独角兽,也是估值仅次于OpenAI和Anthropic的基础大模型公司。
Cohere同样以强大创始团队备受业内瞩目,其创始人之一Aidan Gomez是大语言模型领域开创性论文《Attention is All You Need》的最年轻作者,正是这篇文章首次提出了著名的Transformer架构,成为通用大模型发展的基础模型,ChatGPT就是在这一架构的基础上诞生。
▲Cohere推出的第一个生成式AI应用Coral
Cohere与OpenAI提供的产品类似,但它看到了“数据隐私”这个市场机会,将自己与OpenAI的定位区分开来,选择了ToB赛道,坚定地走商用大模型的路线。其产品基础能力包括三大类:文本检索,文本生成和文本分类,并且可针对客户需求,强调安全性,隐私以及定制化服务。
Cohere的另一大卖点是,不受任何云端平台限制,进而保障资料的私密安全性。它提供灵活性存储和资料隐私保护路径,可使用户实现本地部署,以满足客户资料存储不同位置的需求。
Cohere能迅速转向,找到自己的差异化定位,离不开Aidan及其联合创始人独特的人才观和创业哲学。
Aidan曾表示,Cohere寻找不同背景但对AI非常感兴趣并富有雄心的人:他不一定有大公司的漂亮履历,但是一定要对自己专注的领域有非常高的兴趣和热情,而且不光会写论文,还要有实际动手的能力。
差异化的产品战略,与众不同的团队背景,让Cohere成为通用大模型领域的一股清流。
日前,Cohere发布了全球首个公开可用的多语言理解模型,该模型基于来自母语人士的真实数据进行训练,能够阅读和理解全球超过100种最常用的语言。
再来看巨头Google 。
12月6日,Google DeepMind重磅推出了多模态AI模型Gemini,可以同时横跨文字、图片、影音、程式码等多模态进行学习与理解。
以客服机器人的应用为例,使用Gemini作为模型不仅能够从对话的字面意思上理解客户,更能同时从表情、声调接收到客户话语中的意图,能处理包括音讯、程式码、图像、视讯等内容。

据实测结果,Gemini是第一个在大模型多任务语言理解上超越人类专家的模型,且在32项AI测试中,有30项测验结果超过GPT-4。
凭借强大的性能,Gemini迅速出圈,并且为其母公司Alphabet创造巨大声量。12月7日,Google 母公司Alphabet股价涨幅5.31%,收于136.93美元,总市值达到1.72万亿美元。Google 则计划逐步将这一模型融合进其搜索、广告等其他服务中。
但谈到美国大模型,更值得重视的还是其在产业中的应用进展以及未来想象。
【加速产业落地】
斯坦福大学发布的《2023年人工智能索引报告》中显示,2022年,美国的35个大模型中,只有3个大模型来自于实验室,32个都诞生于产业中。今年,也仍然保持着这一趋势。
2023年3月30日,当外界还沉浸在通用大模型涌现的狂欢中,彭博社凭一己之力将众人的注意力集中到行业新赛道。当天,它对外宣称,自己已构建出迄今为止最大的金融领域数据集,训练了专门用于金融领域大语言模型的LLM,并开发了拥有500亿参数的语言模型——BloombergGPT。

顶着全球首个金融大模型的光环,BloombergGPT依托彭博社大量的金融数据源,构建了一个3630亿个标签的数据集。高金智库分析,它可极大提高金融机构的工作效率及稳定性,协助降本增效。
在降本层面,BloombergGPT可以在投研、研发编程、风险控制及流程管理等方面减少人员投入;增效层面,它既可以通过给定的主题和语境,自动生成高质量的金融报告、财务分析报告及招股书,同时辅助会计和审计方面的工作,还可提炼梳理财经新闻或者财务信息,释放专业人力到更需要人工专业的领域。
天风证券则在报告中指出,由于BloombergGPT比ChatGPT拥有更专业的训练语料,它将在金融场景中表现出强于通用大模型的能力,进而也标志着金融领域的GPT革命已经开始。
BloombergGPT只是一个典型案例,目前,美国金融大模型已呈现出明显的三个“流派”:一是独立全栈自研,强调自主可控;二是在他人的基础上结合自身数据与场景微调,形成契合自身的金融大模型;三是从云端调用,按需接入各类大模型API做私有化部署,科技基础薄弱的中小型金融公司多采用这类方式。
据有关统计数据,美国金融AI约占整体AI领域融资的6.7%。
医疗行业,是美国大模型落地应用的另一片热土,谷歌、微软等科技巨头, Sensely、Enlitic等医疗科技公司,AbSci、Exscientia等生物医药初创企业,以及赛纽仕等CXO(医药外包)企业,都已参与其中。
化合物合成、靶点发现等新药研发业务,电子病历、辅助问诊等医院诊疗业务,则是美国医疗大模型应用的常用场景,CT(电脑断层扫描)、MRI(磁共振成像)等医疗器械在大模型赋能下进一步增强。
众多医疗大模型中,谷歌的Med-PaLM2是被关注的重点。它是第一个在美国医师执照考试(USMLE)的MEDQA数据集上达到“专家”考生水平的大模型,其准确率达85分以上;也是第一个在包括印度AIIMS和NEET医学考试问题的MEDMCQA数据集上达到及格分数的人工智能系统,得分为72.3分。
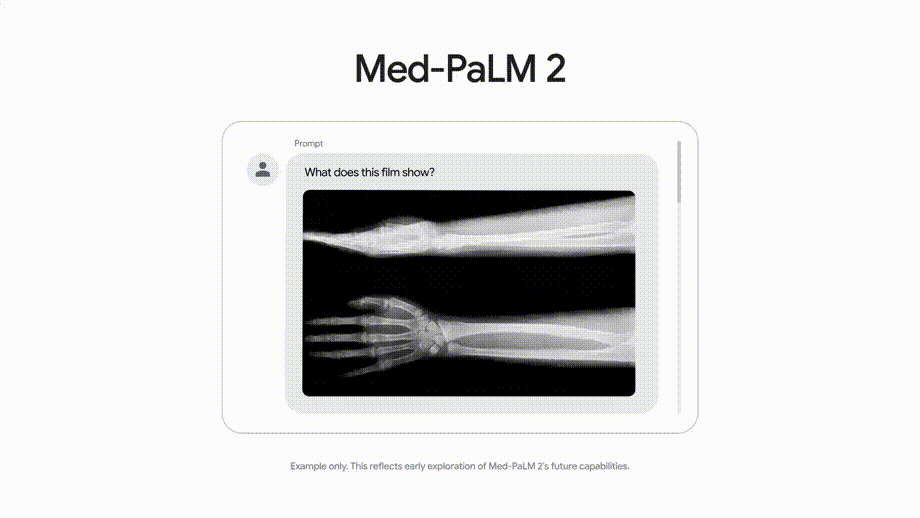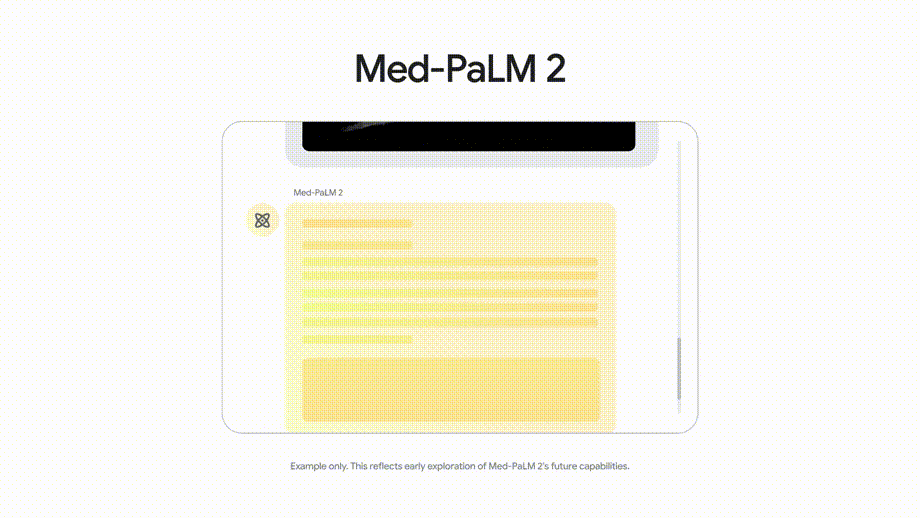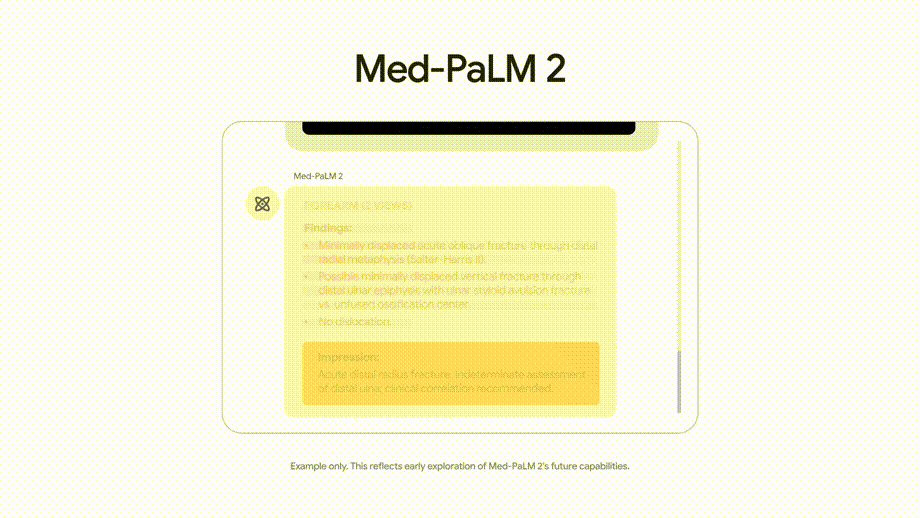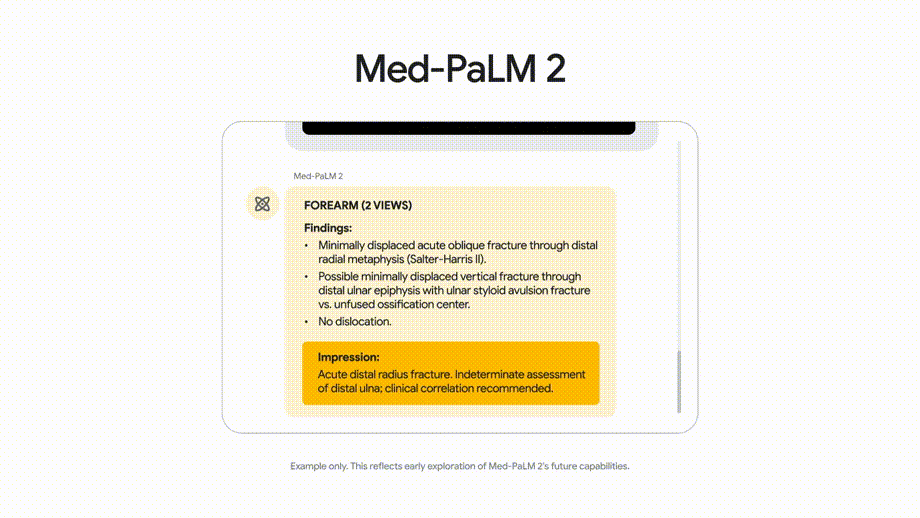
Med-PaLM2也正对行业带来变革性影响。
通过Med-PaLM2,可以分析大规模的生物医药数据,发现与疾病相关的基因、蛋白质和代谢途径,识别潜在的靶点,帮助筛选具有潜在活性的药物分子,从而缩小候选药物的范围,并优先选择具有较高活性的化合物进行后续实验验证。备受时间煎熬的新药研发,则将因此缩短研发周期,降低研发成本。
Med-PaLM2的成功,还刺激谷歌在医疗大模型领域投入更多。
如:与医疗软件公司Epic合作,开发了一种基于ChatGPT的,可向患者自动发送专业医疗信息的工具;谷歌的合作方、护理供应商Carbon Health也基于GPT-4推出了一种AI工具Carby,它可以根据医生病人之间的对话,自动生成诊断记录,大大提高医生的效率和诊断体验。目前Carby已经被130+家诊所、超过600名医疗人员使用,旧金山的一家诊所表示,使用了Carby后,其就诊病人数量增加了30%。
在谷歌之外,AI芯片巨头英伟达也在医疗大模型领域布局多年。
2021年,英伟达宣布与Schrodinger(美医疗资讯技术公司)建立战略合作关系,通过提升其计算平台的速度和精确度,实现快速、准确的评估,加速开发新的治疗方法。
2022年9月,英伟达发布了用于训练和部署超算规模的大型生物分子语言模型——BioNeMo,帮助科学家更好地了解疾病并寻找治疗优解,BioNeMo还提供云API服务支持预训练AI模型。今年7月,英伟达又向生物技术公司Recursion投资5000万美元,支持开发和训练在生物和化学领域的AI基础模型。
教育领域也是美国大模型应用落地的重要场景之一,其核心应用主要集中于语言学习、在线课程与辅助学习三个层面。其标志性案例是美国在线教育组织Khan Academy于4月发布的基于GPT-4模型,具有辅导教学、教案生成、写作训练、编程练习等功能的AI助教Khanmigo。
目前,Khan Academy已经实现商业化运作,付费标准为9美元/月或者99美元/年。其中,辅导教学可以为学生进行一对一辅导。Khanmigo会主动解释答题思路,并引导学生进行答题的思维训练,直至学生自己计算出正确答案;此外,Khanmigo还可以作为写作指导老师,根据人物特征、故事背景等具体细节,提示和建议学生以不同的切入点进行写作、辩论等,释放学生的创造力。
强大的意图理解和自然语言交流能力,以及文本和图像生成能力,让Khanmigo可以真正理解学生,有针对性地给学生提供个性化的学习建议,并且大幅提升教材的供给,包括寓教于乐的课件、丰富的课外资料等,这让教育的“千人千面”有了实现的可能,也正对行业产生重要影响。
综合来看,美国大模型还在加速与产业的融合发展,新的产业革命也正因此发生。
【中国优势与机遇】
从全球范围来看,中美两国引领着大模型的发展。
根据《中国人工智能大模型地图研究报告》,目前全球累计发布大模型202个,其中中美两国大模型数量占全球大模型总数量的近80%。全球大模型之争实际上是中美两国的竞赛。
中国大模型的参与者同样众多,头部科技企业(阿里、百度、腾讯、华为等)、新创公司(智谱AI、百川智能等)、传统AI企业(科大讯飞、商汤科技等)以及高校研究院(清华、复旦、中科院等)均已深度布局,并正逐渐形成互联网巨头通用模型领跑、AI厂商、创业公司及科研院所百花齐放的格局。
虽然目前美国在大模型领域呈现出领跑态势,而且对中国采取了诸如禁止美国企业向中国提供云计算以及大模型训练服务等打压措施,中国大模型依然有着巨大发展机遇,并具备超越美国的基础。
首先是,中国从政府到业界都在力推大模型的发展与赶超。据《金融时报》报道,中国已在全球前十的大模型研发机构中占据四席,分别是百度、BAAI智源研究院、清华大学以及阿里巴巴研究院。百度的“文心一言”、阿里巴巴的“通义千问”等都是我国自研的大模型,其性能足以与美国的大模型一较高下。
Leonis Capital报告分析表示,相较于美国企业更加重视底层研发能力,中国百度、阿里等领先巨头之外的绝大多数企业,更偏框架、行业应用层面的研发,而这种差异将为中国带来巨大机会,让中国在生成式AI应用和大模型行业解决方案应用领域超越美国,最终以应用领先倒逼或支持基础端的赶超。
因为,中国虽然在底层研发技术上相较于美国略显逊色,但却具有超大的市场规模以及丰富的应用场景,可以为大模型的落地应用提供广阔的空间和条件,进而通过行业应用先行来带动整体的突破。
大模型一个很重要的特征是,应用和技术的双轮驱动。也就是说,消费者在使用大模型的时候,并不仅仅是贡献利润,还可以通过数据回环,使大模型获得更多的反馈,从而提升神经网络的能力。丰富的场景可以让大模型更加突出实用性,并匹配需求取得更好的效果,也带动更快的技术发展。
基于这一特征,中国若能依托巨大的市场规模以及丰富的场景,把握住应用这个关键,尊重市场规律,持续从市场应用中获得利润,再反馈给资金和人才的积累,最终在底层技术上突破将是水到渠成的事。
作为国内AI大模型领军者的李彦宏近日也在极客公园创新大会2024上表示,“大模型时代的来临,真正的价值在于原生应用。”
李彦宏认为,大模型本身并不是大多数人的创新和创业机会,原生应用才是。无论对于大厂,还是中小企业,创业者,原生应用都是很大的机会。
李彦宏说,看到媒体、社会、公众主要的兴奋点还在基础模型上,没有转到AI原生应用上,“我多多少少有点着急。”最近几次公开发言,也括公司内部讲话,他也都是在不停的强调。“我们一定要去卷AI的原生应用,要把这个东西做出来了,你的模型才有价值。”
事实上,中国已经在互联网与移动互联网领域,通过丰富的场景以及应用创新取得领先的发展,并最终带动整个科技产业的进步,在大模型领域,这一趋势也正在继续。但对比中美在互联网领域的发展,有一点倒是值得中国大模型企业现在就高度重视:更早地在海外布局,朝向全球化发展。
如今的中国企业,也更有基础出海,在全球市场找到更加广阔的发展空间。
欢迎关注【华商韬略】,识风云人物,读韬略传奇。
版权所有,禁止私自转载
部分图片来源于网络
如涉及侵权,请联系删除




