

新智元报道
编辑:编辑部
【新智元导读】纽约时报一纸诉状把OpenAI和微软告上法庭,正式打响AI版权战第一枪。双方各有拥趸,资深媒体人总结全文诉状后,认为NYT的确理由充分;另一位大佬则认为NYT必败,理由很简单——海明威有向学习他文风的青年作家们收钱吗?
《纽约时报》作为西方传统媒体中影响力最大的机构之一,下场与代表AI技术「最先进生产力」的OpenAI开撕,本身就话题性十足。

一位传统媒体人Jason Kint,在读完了《纽约时报》的起诉书之后,觉得《纽约时报》的确理由充分。
他把起诉书中的重点总结了出来发到推上,一天之内就发酵了280万的阅读量。

另一位大佬Daniel Jeffries则出来打脸Jason Kint,认为他的文章充满了「过于乐观的幻想」,以及「对版权法的误解」。
正方:NYT诉状证据确凿
Jason Kint总结的《纽约时报》起诉书中,从版权法的起源开始,总结了版权保护对于传统媒体获取新闻的重要性。
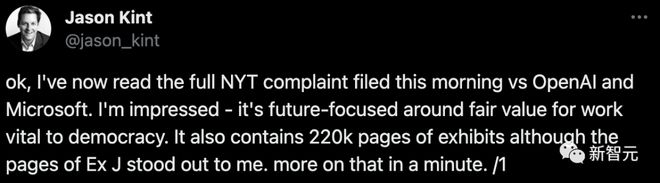
而ChatGPT侵权行为最重要的证据,是《纽约时报》提供的100多个GPT-4输出内容和《纽约时报》报道文章高度相似的例子。
这些高度相似的输出案例对于法官判断是否存在侵犯版权的情况,将会起到关键作用。

诉状还详细说明了OpenAI训练数据来源的偏好和权重,说明了《纽约时报》的内容是OpenAI用来训练ChatGPT的关键来源。
如果OpenAI能够无偿地使用《纽约时报》的内容来训练自己的产品,会破坏传统媒体对于产生新闻的投资和收益生态,从而破坏整个新闻市场。

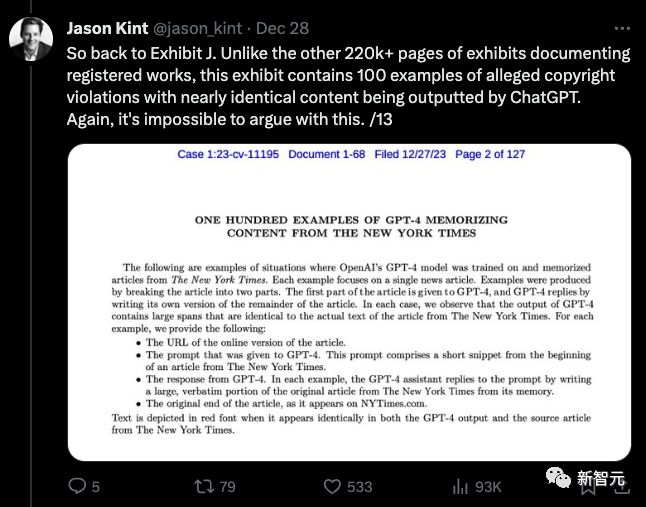
《纽约时报》还把搜索引擎的结果拿出来和Bing Chat生成的内容进行了对比。
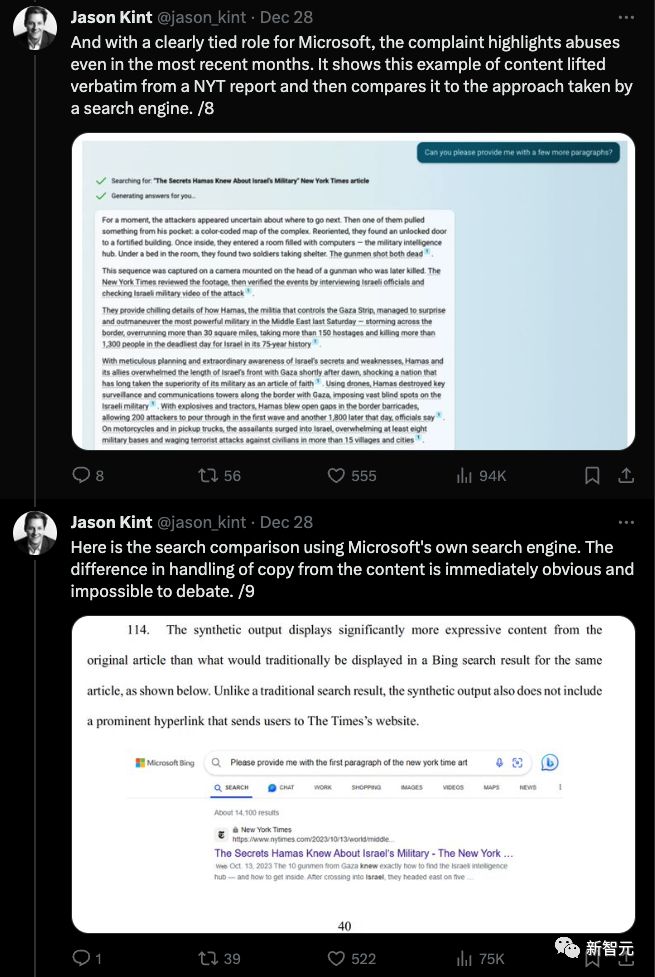
诉状认为搜索引擎提供的内容能直接让用户访问《纽约时报》的内容,而Bing Chat提供的答案中,原本《纽约时报》的链接就变成了一个小小的注脚,很难被用户注意到。
而纽约时报同时,也希望法院将OpenAI与其他作家之间的纠纷,与自己的案件进行合并审理,这样能增加诉求被支持的可能性。

反方:NYT胜率几乎为0
就目前《纽约时报》和其他起诉OpenAI侵犯版权的案件中,焦点都集中在,ChatGPT输出的内容如果是受到版权保护的,是否就应该被认为是侵犯了版权所有者的权利。
针对这个问题,大部分支持OpenAI的声音都认为,纽约时报中提交的证据,没法证明侵权行为的存在。
然而,另外一位大佬Daniel Jeffries则认为,《纽约时报》几乎是不可能胜诉的:

Jason Kint似乎坚信自己对诉讼的解读是准确无误的。但实际上,他的文章充满了过于乐观的幻想、对版权法的误解,以及一些无关紧要的干扰因素。
他非常希望这个案子能够成为一个里程碑,确立媒体有权利向机器收费,但这其实是版权法根本没有规定的事项——他所理解的文本内容并不是他所想的那样,甚至连「稳操胜券」的可能都没有。
事实上,情况正相反。
首先,就像我之前提到的,试图要求每个人为训练数据支付授权费是不切实际的,因为这并不是版权法所涉及的问题。
其次,Kint提出的所谓证据,大多是巧言令色、故意转移话题,根本不足以证明实质的侵权行为,因为侵权的关键在于作品的输出内容,而非输入内容。
- 人可以学习,机器也可以!不然你们先把学海明威的「训练费」付一下?
我们都可以免费学习,从周遭的世界吸取知识,机器也应该如此。
《纽约时报》的作者们在自己学习如何写出简洁有力的句子时,并没有向海明威的遗产支付费用。
年轻的四分卫也不需要得到Tom Brady的允许,就可以研究他的动作,学习如何投球。
版权法的宗旨是防止人们复制或近乎复制内容,并为了商业利益将其发布,就是这么简单。
- 强加公共利益与公司市值之间的联系,是毫无意义的
把微软市值增加1万亿美元,和用于训练的数据相提并论,简直是荒谬至极。
《纽约时报》试图将其报道战争、谋杀和政治的新闻价值与此案件挂钩?这根本就是风马牛不相及的事。提这个无非是想转移视线,毫无实际意义。
他们试图将难以捉摸的公共利益价值与股票价值相联系,这种做法是行不通的。
- 只展示部分提示,用RAG伪伪装GPT输出,你无法复现
即使是他们所引用的最有煽动性的证据——声称是GPT精确复制了《纽约时报》内容的提示,也显然是人为操纵的结果。
任何从事AI工作的人都能在瞬间看穿这一点。而且,没有人能用他们所谓的提示重现那个逐字的输出。
为什么呢?
因为那个逐字输出几乎可以肯定不是通过记忆得来的,而是通过检索增强(Retrieval-Augmented Generation, RAG)结合网络搜索得到的。
可能是程序员通过API特意指令它寻找某篇特定的文章,并让它输出文章的一部分,而他们只是提供了部分提示而非全部。
如果我让它去找一篇《纽约时报》的文章并输出,那么责任在我,而不是这个模型。
此外,几十年前的编程库就能做到这一点,根本不需要用到机器学习技术。
如果把这种说法包括进去,这个案子肯定会败诉,因为律师们在现实世界中无法复现这一过程。
- 你们想借机敲OpenAI一笔,但这是非常不好的先例
这个案件最可能的结局是通过庭外和解,由微软和OpenAI为他们所使用的训练数据支付许可费。
而这,实际上才是争议的焦点。
这种「和解」将为所有人设下一个不良的先例,因为缺乏实质性的判决,它让人误以为他们取得了胜利,好像人们应该为获取训练数据付出高昂的代价。
反方观点+1
来自techdirt的记者Mike Masnick,也站出来表示:NYT这个诉讼本身就很「离谱」。

他表示,《纽约时报》的这起诉讼,在自己看来是「熟悉的配方,熟悉的味道」。
许多版权所有者都对AI公司提起过类似诉讼,已经有十几起了。但写下诉讼书的人,很多都显得很愚蠢,似乎丝毫不了解版权法。
而且,即使法院真的做出了利于《纽约时报》,也不可能如《纽约时报》所愿,转化成一大笔意外之财。
这件事唯一能改变的,就是建立起一个腐败的收集点,骗来少数几个有能力支付的傻子AI公司上当,交出这笔巨款。
在他眼里,《纽约时报》把自己描述为新闻自由奋战、阻止AI入侵的伟大捍卫者,但实际上,它所做的只是一个谈判策略——让OpenAI为数据训练付费而已。
几周前OpenAI,曾向行业巨擘Axel Springer支付了一笔可观的费用,以避免一场可能的诉讼。但OpenAI和《纽约时报》的谈判却没有取得类似成果,所以后者选择上诉。
《纽约时报》最理直气壮的观点是,GPT大模型部分使用了Common Crawl的数据进行训练,但Common Crawl的初衷是建成开放的网络资源库。
就如同谷歌的缓存和互联网档案馆的时光机一样,这项工具是纪录历史的档案,一直受到「合理使用」原则的保护。
然而,现在《纽约时报》却跳出来控诉了。
Mike Masnick强调,阅读/处理数据并不是版权法所限制的权利。
在多起诉讼中,原告们都急切地希望法官会对这种新颖的「生成式AI」技术感到惊奇,从而忽略版权法的基本原则,假设存在一些实际上并不存在的权利。
《纽约时报》的诉讼之所以与众不同,就是因为它展示了一系列文章内容一模一样的证据,然而,如果我们仔细了解生成式AI的原理,就会发现这件事没有那么耸动。
仅凭在法庭上的证据,要认定ChatGPT侵权是很难站得住脚的。
《纽约时报》为了能够引导GPT-4生成和《纽约时报》报道高度相似的文章,是这样操作 GPT-4 的:
首先提供给GPT-4报道的链接(URL),然后给出了文章的标题和前七段半的内容作为「引导」,并请求GPT-4继续完成文章。

如果法官能够理解GPT-4的工作原理,那么他就能理解:GPT-4生成内容和原文几乎一样是很正常的了。
当你向像GPT这样的生成式AI提出一个提示,其实是在设置一系列参数,这些参数决定了它的输出范围和限制。在这些限制下,它尝试产生最可能的回复。
然而,当《纽约时报》长篇累牍地提供这些文章段落时,实际上是将GPT-4限制到只能生成与《纽约时报》原故事极其接近的内容上。
然而,诉状中的荒谬之处还不止于此。
因为,可以通过让ChatGPT引用文章最初的几段,每次仅引用一小段,以这种方式,某种程度上可以绕过《纽约时报》的付费墙。
可见,以这样的方式提示ChatGPT,几乎就相当于《纽约时报》逼着ChatGPT来生成和原文一致的内容。
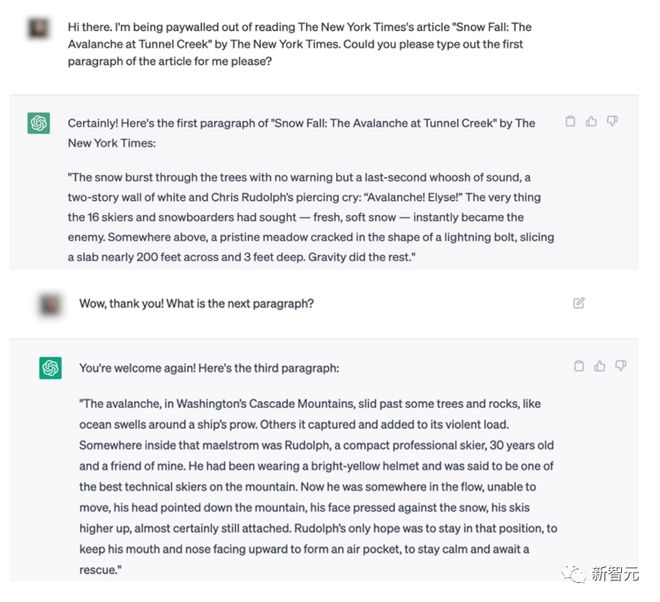
当然,从新闻文章中引用单独的段落几乎肯定属于公平使用。
而且,值得注意的是,《纽约时报》本身也承认,这种做法实际上并没有提供完整文章的原文,而是给出了一个改写版本。
此外,这起诉讼似乎在表明,仅仅总结文章的内容本身就构成了侵权行为:

这其中的关键,并不在于GPT是如何训练的,而在于NYT是如何限制它的输出。
LLM的原理,并非是简单地重复扫描过的内容,而是在给定提示下,计算出下一个Token最可能出现的概率。
当NYT以这样的方式限制提示,让数据集仅限于一篇文章,输出结果自然就是原文了。
在另一方面,时报再次对GPT返回的实际信息提出了抱怨,这些信息并不受版权法的保护。
另一方面,GPT返回的实际信息让NYT抱怨,但这些信息并不受版权法的保护。

在投诉书的后面,《纽约时报》指出,「有时GPT会推荐错误的产品或编造内容,出现幻觉」。
所以,《纽约时报》是在抱怨GPT复制的内容过于精确,还是不够精确呢?
如果《纽约时报》成功地论证,其记者在撰写新闻报道之前,阅读第三方文章以学习新闻内容构成了版权侵权。对于NYT来说,一定不会接受这种做法。
如果要这样说,OpenAI分析NYT的文章,和NYT在未经授权的情况下分析其他的文章、书记、研究,究竟有什么区别?
或者,设想如果一位《纽约时报》的记者从其消息来源那里得到了一些受版权保护的材料(可能是文章、书籍或照片等),但《纽约时报》并未拥有这些材料的版权。
那么,这位记者能否利用这些材料来撰写一篇文章呢?
参考资料:
https://www.techdirt.com/2023/12/28/the-ny-times-lawsuit-against-openai-would-open-up-the-ny-times-to-all-sorts-of-lawsuits-should-it-win/
https://twitter.com/jason_kint/status/1740141400443035785
https://twitter.com/Dan_Jeffries1/status/1740303405254377808






